The rise of generative AI has propelled many companies to integrate these technologies within their business models. One prevalent method involves creating AI systems capable of answering questions by retrieving information from a document database. A key technique in this domain is Retrieval Augmented Generation (RAG), which has sparked the advent of vector databases.
The Vector Database Shift
Vector databases have emerged as a key technology, storing and searching vast arrays of embeddings, or vector representations, which signify document relevance through similarity metrics. Startups in this space have secured hundreds of millions in funding, promising to simplify RAG by enabling efficient embedding searches. The real world is coming industry, one asset class at a time.
These vector databases don't store the actual text but rather the embeddings, making it harder to interpret what exact information they hold. This leads to a pressing question: Are these embeddings secure?
Challenges of Inversion
The process of recovering text from these embeddings presents a significant challenge. Embeddings are the byproduct of neural networks, which apply sequences of complex operations to input data. This transformation is so opaque that the individual values in an embedding vector seem like random numbers.
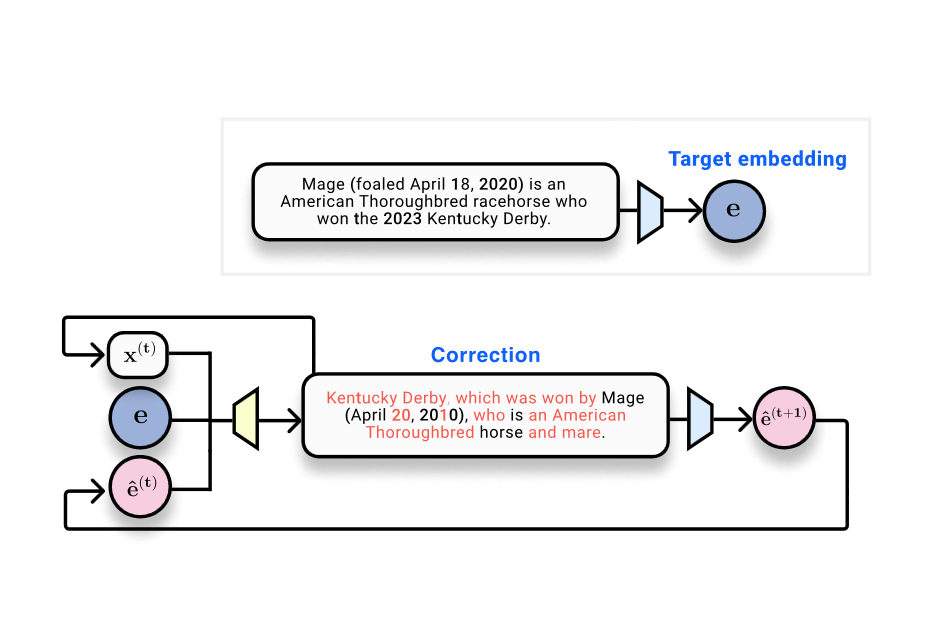
Yet, current research indicates that these embeddings can potentially be inverted back into text, raising alarms about data security. If embeddings can be reversed, what's stopping a breach from revealing sensitive information stored in seemingly innocuous numbers?
Exploring Inversion Techniques
Inspired by the computer vision community's success in reversing image embeddings, researchers are now examining text. They've developed a method called vec2text, a kind of iterative optimization within embedding space, which shows promise in reconstructing text with high accuracy.
This technique has advanced to a point where it can almost perfectly reconstruct text sequences, raising concerns about how secure embedding vectors truly are. When physical meets programmable, the blending isn't always smooth.
Future of Text Embeddings
This breakthrough raises critical questions. If text embeddings can be perfectly inverted, how do we secure such data? Can we develop models that maintain utility while obfuscating the originating text? These questions underscore the need for strong security measures as vector databases proliferate.
As AI infrastructure continues to evolve, the industry must address these vulnerabilities to ensure that the data driving our AI systems remains protected. Tokenization isn't a narrative. It's a rails upgrade.


